
AI는 이제 실험 단계를 넘어 기업 운영의 필수 과제가 됐다. 하지만 이를 전사 차원으로 확장하는 것은 완전히 다른 차원의 문제다.
많은 산업에서 AI 파일럿은 통제된 환경에서 가치를 입증하고도, 실제 엔터프라이즈 배포 단계의 문턱에서 멈추는 경우가 많다. 문제는 모델 성능이나 컴퓨팅 자원, 데이터 부족이 아니다. 핵심은 데이터를 떠받치는 아키텍처에 있다. 그리고 대부분의 제조 기업은 잘못된 방식으로 이를 구축해왔다.
Kearney 추정에 따르면, 제조업 전반에서 AI가 창출할 수 있는 연간 가치는 약 8,900억 달러에 이른다. 이는 전 세계 제조업 부가가치의 약 5% 규모다.1 이 수치는 AI를 활용하는 제조기업들이 이미 일부 운영 영역에서 입증하고 있는 생산성, 자산 신뢰성, 에너지 집약도, 품질 성과의 측정 가능한 개선 효과를 의미한다. 입증된 가치와 실제 포착된 가치 사이의 격차는 거의 전적으로 하나의 변수로 설명된다. 바로 기저 데이터가 AI 에이전트가 그 위에서 추론할 수 있을 만큼 충분한 맥락(context)을 담고 있는가이다.
1. Analysis in this article draws on World Bank manufacturing value added data (2024), work done by CESMII, and Kearney proprietary research.
1. 왜 제조 AI는 데이터 계층에서 실패하는가
지난 10년 동안 지배적인 데이터 전략은 축적(accumulation)이었다. 제조기업들은 센서 측정값, 장비 로그, 공정 이벤트를 중앙화된 데이터 레이크로 옮겼다. 규모가 커지면 언젠가 인사이트가 나올 것이라는 가정에서였다. 그러나 대부분의 경우, 그런 일은 일어나지 않았다.
원시 산업 데이터(raw industrial data)는 그 자체로는 거의 아무런 의미 구조(semantic structure)를 갖지 않는다. 예를 들어 장비 태그는 식별자에 불과하고, 센서 측정값은 숫자이며, 타임스탬프는 순서상의 위치일 뿐이다. 이러한 신호가 무엇을 의미하는지, 서로 어떻게 연결되는지, 생산 성과와 어떻게 이어지는지를 정의하는 계층이 없다면, AI 시스템은 작업자의 교정 조치와 근본 원인, 정상적인 공정 변동과 초기 고장 신호, 품질에 중요한 파라미터와 무관한 파라미터를 구분할 수 없다.
- 작업자의 대응 조치와 실제 근본 원인
- 정상적인 공정 변동과 초기 이상 신호
- 품질에 영향을 주는 핵심 파라미터와 의미 없는 파라미터
2025년 500명의 비즈니스 리더를 대상으로 한 조사에 따르면, 응답자의 74%는 단절된 데이터 사일로나 파편화된 인프라를 AI 확장의 가장 큰 장벽으로 보고 있다. 제조업에서는 AI 오류가 수율, 안전, 규제 준수에 영향을 미치기 때문에, 잘못된 신호에 따라 행동할 때의 비용은 재무적 손실을 훨씬 넘어선다.
제조업에서는 이 문제가 여러 사업장으로 확산되면서 더욱 복잡해진다. 예를 들어 한 공장의 온도 센서가 TT101로, 다른 공장의 동일한 의미를 가진 센서가 TMP101로 명명되어 있다면, 물리적으로는 같은 의미를 가지더라도 통합 장벽이 발생한다. 그 결과 모든 사이트 간 배포와 모든 유즈케이스마다 맞춤형 개발이 필요해진다. 새로운 애플리케이션이 생길 때마다 같은 데이터 연결 작업을 반복해야 하고, 새로운 사업장이 추가될 때마다 같은 매핑 작업을 다시 수행해야 한다.
더 깊은 위험은 AI가 해석할 수 없는 데이터를 기반으로 추론하려고 할 때 발생한다. 의미론적 맥락이 없으면 모델은 실무자들이 말하는 합성적 일관성(synthetic coherence)을 만들어낸다. 이는 내부적으로는 일관되고 겉보기에는 그럴듯하지만, 실제 운영 관점에서는 잘못된 출력이다.
예를 들어 생산 데이터를 검토하는 AI가 공정 맥락 없이 불량률 상승과 작업자의 라인 속도 감소 사이의 상관관계를 발견했다고 하자. 이 AI는 불량을 줄이기 위해 라인 속도를 높이라고 권고할 수 있다. 그러나 실제로는 작업자의 라인 속도 감소가 원인이 아니라 문제를 완화하기 위한 교정 조치였을 수 있다. 규제 산업 환경에서 이런 유형의 오류는 하나의 배치(batch)에만 머물지 않는다. 그 결과 제조업에서는 AI가 파일럿에서는 작동하지만, 확장 단계에서는 파편화되는 현상이 반복된다.
2. 미디엄·하이테크 제조업이 8,900억 달러 규모의 AI 기회를 이끈다
전 세계 제조업의 AI 가치 기회에 대한 Kearney의 분석은 단순한 시장 규모뿐 아니라 데이터 복잡성을 반영한다. 가장 큰 기회는 미디엄·하이테크 제조업 분야에 집중돼 있으며, 규모는 약 3,560억 달러에 달한다. 주요 시장은 아시아·유럽·북미에 집중되어 있다. 기계 및 운송 산업이 2,260억 달러 규모로 뒤를 잇는다. 식음료 및 담배 산업은 1,130억 달러 규모의 기회를 보유하고 있는데, 식품 안전 규제로 인해 오염 추적성과 배치 계보(batch genealogy) 관리 요건이 강화되면서, 데이터 맥락을 연결하는 문제가 더욱 시급해지고 있다. 화학 산업 역시 1,110억 달러 규모의 기회를 보유하고 있다. 이 산업에서는 원재료, 공정 조건, 결과 간 상호의존성이 매우 복잡해, 평면적인(flat) 데이터 아키텍처 만으로는 이러한 관계를 제대로 표현할 수 없다.
▶ 방대한 기회를 가져오는 제조업 AI
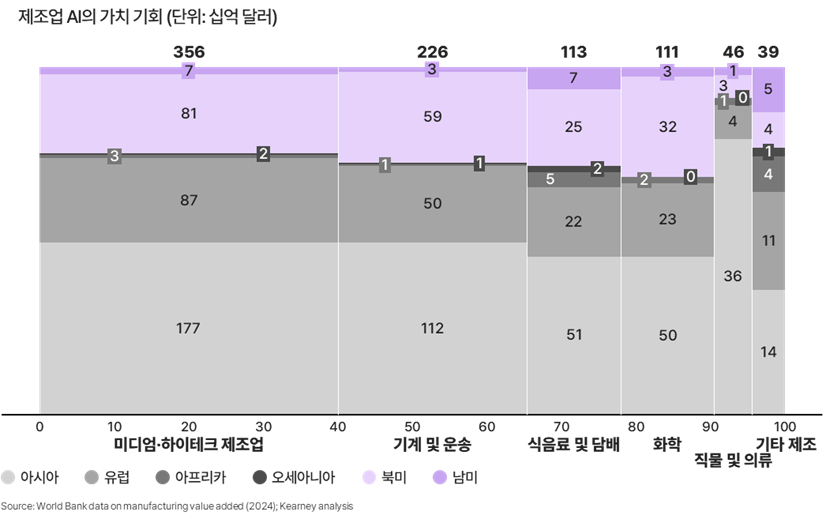
이 산업들은 AI를 실제 운영 환경에 적용하기 위해 훨씬 높은 수준의 기술 역량과 데이터 정합성을 요구한다. 생산 공정 자체가 비선형적으로 움직이고, 하나의 결과가 여러 시스템과 시간 흐름에 걸쳐 복합적으로 연결되어 있기 때문이다. 또한 제조업에서 AI 오류는 단순한 운영 비효율 수준으로 끝나는 것이 아니라, 제품 리콜, 생산 중단(downtime), 규제 대응 리스크로 이어질 가능성이 크다. 다만 이 8,900억 달러 규모의 기회 역시 제조기업이 AI 추론에 필요한 데이터 기반을 갖추고 있다는 전제가 있어야 현실화될 수 있다. 하지만 대부분의 제조기업은 그 기반을 충분히 확보하지 못한 상황이다.
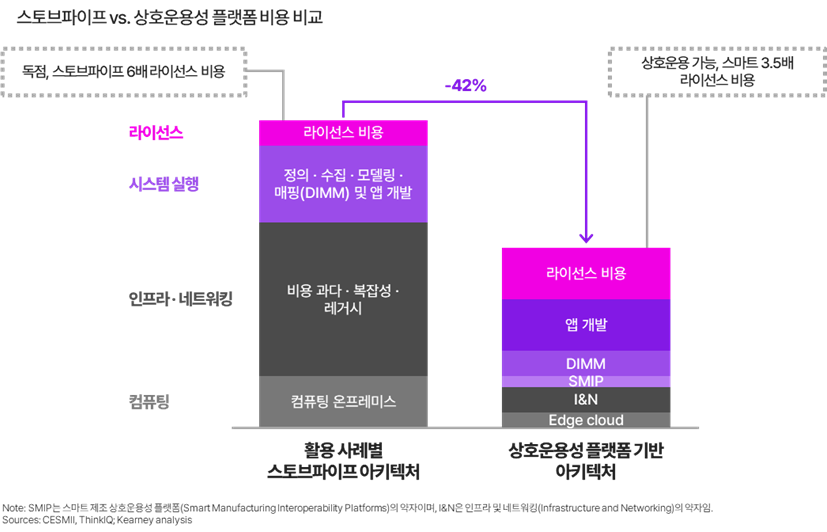
3. 스토브파이프형 아키텍처는 비용이 40% 더 들고도 AI를 확장하지 못한다
전사 규모로 AI 가치를 포착하는 제조기업에는 공통된 아키텍처적 결정이 있다. 이들은 애플리케이션을 그 위에 구축하기 전에 먼저 맥락 계층(context layer)에 투자했다.
객체 지향 정보 모델(object-oriented information models)과 지식 그래프(knowledge graphs)를 기반으로 하는 맥락 계층은 모든 자산이 무엇인지, 각 파라미터가 무엇을 의미하는지, 그것이 다른 자산과 어떻게 연결되는지, 그리고 생산 성과와 어떻게 이어지는지를 표준화한다. 이 기반이 존재하면 한 사업장에서 훈련된 AI 모델을 다른 사업장으로 이전할 때 재엔지니어링이 필요하지 않다. 품질 실패를 조사하는 에이전트는 엔지니어 팀이 수동으로 전체 그림을 재구성할 필요 없이, 소재 계보, 장비 이력, 공정 파라미터를 동시에 탐색할 수 있다.
비용 근거도 명확하다. CESMII의 분석은 스토브파이프형 아키텍처와 상호운용성 플랫폼 기반 아키텍처를 비교한 결과, 유즈케이스 전반에서 중복 통합 작업이 제거되면서 총소유비용(TCO)이 42% 감소한다는 점을 보여준다.
▶ 전통적으로 스토브파이프 아키텍처는 제조 애플리케이션을 확장하지 못하지만, 상호운용성 플랫폼이 해결책이 될 수 있음
4. 운영 사례: 더 빠른 조사, 낮은 리콜 리스크, 더 나은 수율
성과 차이는 실제 운영 현장에서 뚜렷하게 드러난다. 예를 들어, 수백 개의 자산(asset)과 단절된 시스템으로 운영되던 글로벌 시리얼 제조기업은 오염 추적 조사에 수주가 걸리는 문제를 겪고 있었다. 그러나 농장에서 소비자까지 이어지는 가치사슬 전반에 걸쳐 소재, 배치, 자산, 이벤트 데이터를 연결하는 의미론적 맥락 계층을 구축한 이후, 동일한 조사를 수 시간 내에 완료하는 데 성공했다. 경제적 효과는 수천만 달러에 달했으며, 핵심 성과는 리콜 리스크 감소와 수율 효율 개선에서 나타났다. 이 차이는 운영 단계에서도 확인된다. 다음의 시나리오는 동일한 AI 모델이라도 의미론적 맥락 계층 구축 여부에 따라 결과가 얼마나 달라지는지를 보여준다.
▶ Hand Dish Co.의 베를린 공장의 AI 활용 트러블슈팅(문제해결) 사례
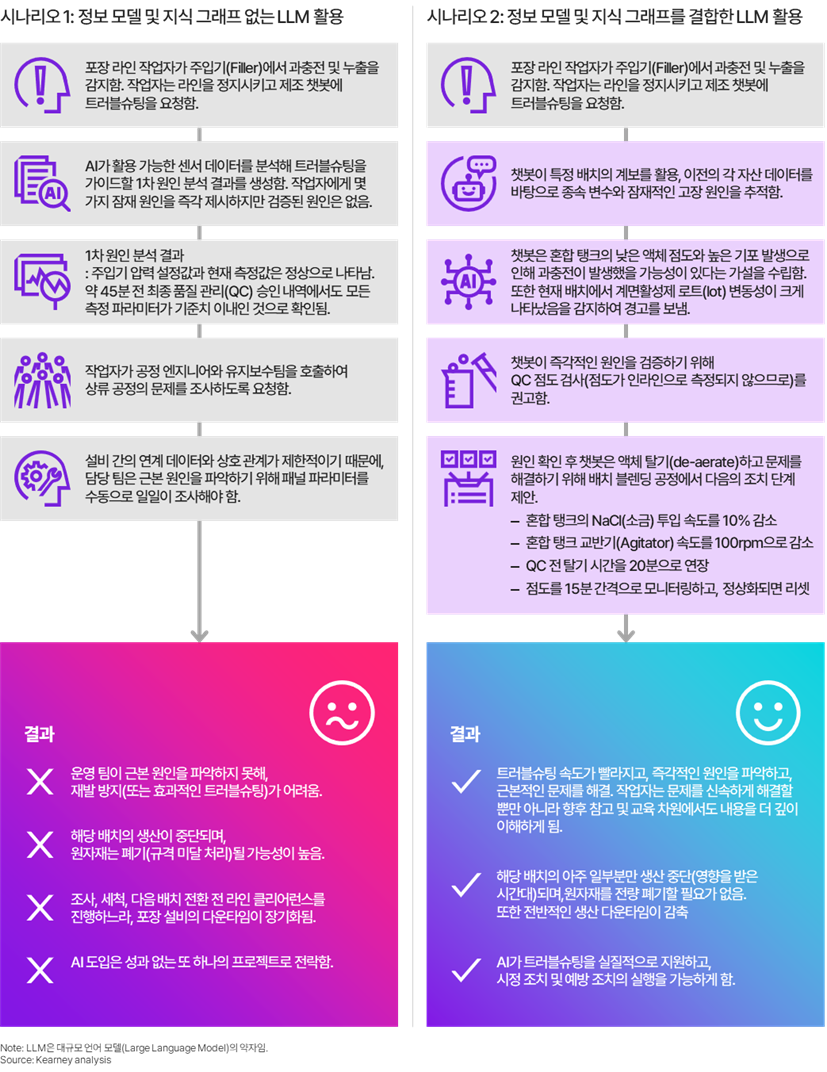
의미론적 맥락 계층(Semantic Context Layer)이 없는 경우
전통적 아키텍처에서는 포장 라인 작업자가 과충전 및 누액이 발생한 병을 발견하고 제조 AI에 문제 해결을 요청한다. 시스템은 접근 가능한 센서 데이터를 검토하고 몇 가지 잠재 원인을 제시하지만, 검증된 근본 원인을 도출하지는 못한다. 충전 압력은 정상으로 보인다. 45분 전의 마지막 품질관리 릴리스도 모든 파라미터가 허용 범위 내에 있음을 보여준다. 장비 간 데이터가 서로 연결되어 있지 않기 때문에, 운영팀은 라인이 정지된 상태에서 패널 파라미터를 수동으로 뒤져야 한다. 해당 배치는 동결되고, 원재료는 폐기될 가능성이 높으며, 조사는 재발 방지를 위한 신뢰 가능한 근거를 만들어내지 못한다.
의미론적 맥락 계층(Semantic Context Layer)이 있는 경우
이 경우 동일한 질의는 구조화된 응답을 생성한다. AI는 배치 계보를 활용해 앞선 모든 자산의 종속 변수를 추적하고, 믹스 탱크에서 높은 기포 발생으로 인한 낮은 점도를 식별하며, 현재 배치에서 계면활성제 로트 변동성을 표시한다. AI는 즉각적 원인을 확인하기 위해 점도 검사를 권고한 뒤, 확인 후의 구체적 조치도 제시한다. 즉, 염분 첨가 속도를 줄이고, 교반기 속도를 낮추며, 탈기 시간을 연장하고, 15분 간격으로 점도를 모니터링하도록 권고한다. 배치 전체가 폐기되는 대신 영향을 받은 부분만 격리되고, 다운타임은 단축되며, 교정 조치가 문서화된다.
두 시나리오는 동일한 AI 모델을 사용한다. 결과를 결정하는 것은 전적으로 AI가 배치의 전체 계보를 가로질러 추론할 수 있는지, 아니면 눈앞의 데이터만 볼 수 있는지에 달려 있다.
▶ 3계층 모델의 작동 방식

5. 제조기업에는 아키텍처 격차가 고착되기 전 3~5년의 시간이 있다
제조업 AI를 구동하는 모델은 이미 범용화 단계에 들어섰고, 성능도 빠르게 발전하고 있다. 향후 3~5년 간의 경쟁 우위는 ‘어떤 AI를 도입했는가’가 아니라, ‘데이터 인프라가 엔터프라이즈 배포에 필요한 속도(Speed), 규모(Scale), 정확성(Accuracy) 수준으로 AI 추론을 지원할 수 있는가’에 의해 결정될 것이다.
▶ 제조 분야 AI 활용의 경쟁 우위는 하위 데이터 인프라에 의해 결정됨

맥락 중심 아키텍처를 조기에 도입한 기업들은 시간이 지날수록 누적되는 이점을 확보하고 있다. 의미론적으로 구조화된 데이터로 훈련된 AI 모델은 더 빠르게 개선된다. 사이트 간 배포는 엔지니어링 프로젝트가 아니라 설정(configuration) 작업이 된다. 소재 계보, 장비 출처, 공정 관계에 동시에 접근할 수 있는 에이전트는 포인트 솔루션 아키텍처가 만들어낼 수 없는 인사이트를 제공한다.
유즈케이스별로 하나씩 구축하고 있는 제조기업은 단순히 맥락 계층 투자를 미루고 있는 것이 아니다. 그들은 데이터 구조, 명명 규칙, 시스템 경계에 대한 가정을 각 배포에 내장함으로써, 나중에 통합 아키텍처가 한 번에 해결했을 문제를 더 어렵고 더 비싸게 만들고 있다.
더 깊은 변화는 단지 아키텍처에만 있지 않다. 선도 제조기업은 분석을 위해 더 많은 데이터를 클라우드로 옮기는 것이 아니다. 이들은 의미(meaning)를 이동시키고 있다. 즉, 운영 맥락을 설명하는 가볍고 구조화된 정보를 분산된 생태계 전반에 이동시키고 있다. 에이전트는 데이터 원천에 배포된다. 원시 신호(raw signals)가 이동하는 것이 아니라, 인사이트가 이동한다. 전사 AI의 비용 구조가 바뀌고, 지능이 사업장, 공급업체, 시스템 전반에서 누적되는 속도도 달라진다. 이것이 실제 현장에서의 생태계 확장성(ecosystem scalability)이며, 일단 구축되면 따라잡기 점점 어려워지는 경쟁 포지션이다.
8,900억 달러의 기회는 균등하게 분배되지 않는다. 그것은 맥락 문제를 먼저 해결한 조직에 집중되고, 그 이후부터 복리처럼 누적된다.
Kearney의 이 분야 작업은 스마트 제조 상호운용성 플랫폼(SMIP, smart manufacturing interoperability platforms)을 중심으로 구축되어 있다. 이는 전사 규모에서 맥락 계층을 제공하는 아키텍처 표준이다.




